Over the summer, I've been replicating some ML experiments in code and this is a blog post summarizing some of my lessons learned and some of the findings in this. The entire repository is located here
Attention Visualizations
Next, I wanted to see what tokens the different layers pay attention to and how that affects their predictions. So my thought process was as follows.
- Implement the attention mechasnism "from-scratch" via The Annotated Transformer.
- Use their interpretability tools to visualize attention in GPT-2
- Visualize this attention mechanism for other models like Mistral and Mixtral.
So consider the sentence "Keane wants to eat a pizza". I essentially wanted to examine what exactly the models were paying attention to across the layers and across the heads in your MHA module. Consider the first and last layers and the first and last attention heads. What do they pay attention ?
visualize_model_attns(model, tokenizer, "Devin wants to go to Hong Kong", view_layers=[0, 23], view_heads=[0, 8])
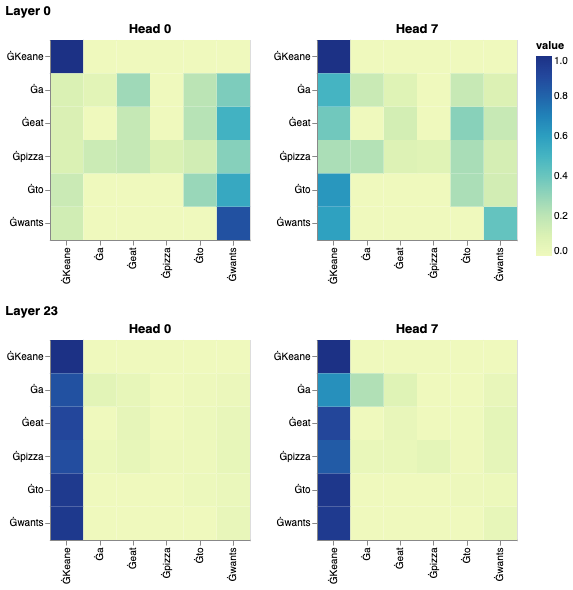
What about across all the attention heads in both these layers ?
visualize_model_attns(model, tokenizer, "Devin wants to go to Hong Kong", view_layers=[0, 23], view_heads=list(range(0, 8)))
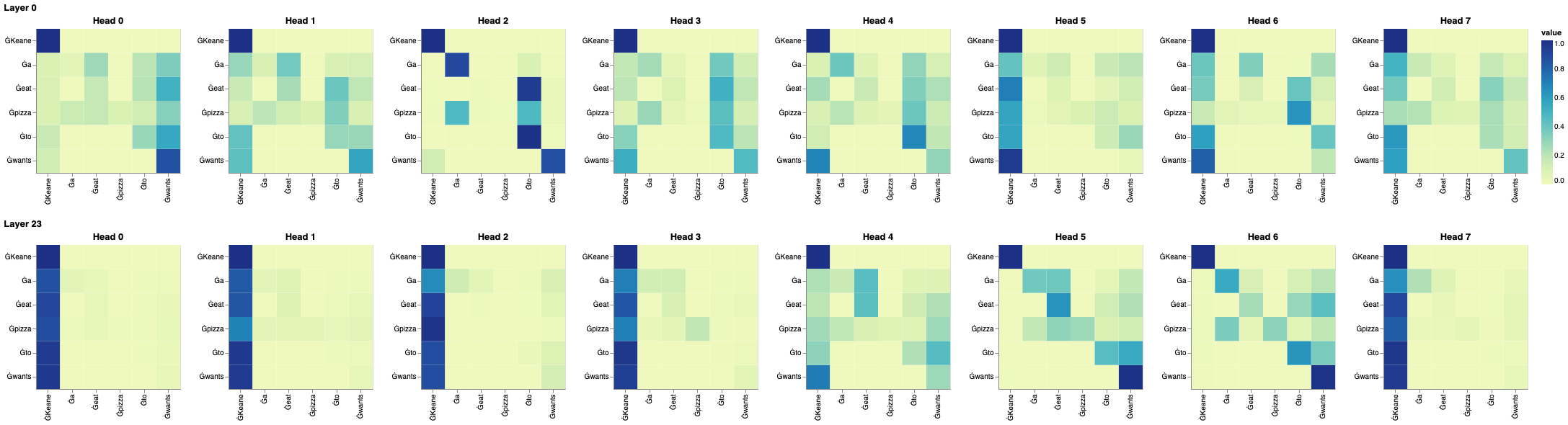
I've generated a bunch of such visualizations for GPT-2 but was not able to discern some pattern of paying attention when understanding sentences.
Experts Investigation
Next I wanted to tackle sorting out what each of the experts in Mixtral learned. I got the idea from listening to Trenton Bricken and Sholto Dougals on Dwarkesh's Podcast. So I started off with simple token percentages. Essentially how many tokens out each dataset go to each of the experts. I set up the "hook" for discerning hooks as follows
def get_print_token(prompt: str, layer_num:int):
ids = tokenizer.encode(prompt, add_special_tokens=False)
tokens = tokenizer.convert_ids_to_tokens(ids)
pos_to_token = {i: token for i, token in enumerate(tokens)}
def print_tokens(module, input, output):
_, topk_index = t.topk(output, 2, dim=1)
# topk_list of of the shape [S_l, 2] where S_l is the length of the sequence
topk_list = topk_index.tolist()
for i, topk in enumerate(topk_list):
token = pos_to_token[i]
topk = tuple(topk)
token_to_expert[token].append(topk)
expert_1, expert_2 = topk
expert_to_token[f"Layer {layer_num}"][expert_1].add(token)
expert_to_token[f"Layer {layer_num}"][expert_2].add(token)
return print_tokens
hooks = []
for layer_num, layers in enumerate(model.layers):
hook = layers.block_sparse_moe.gate.register_forward_hook(get_print_token(data, layer_num))
hooks.append(hook)
By appending this hook, I'm able to print which token is going to which Layer and get a loosey-goosey understanding of what is happening on a token-by-token basis. But this wouldn't scale. So for a whole dataset, I kept 2 dictionaries - one for the first layer's experts and the second for the last layer's experts. Furthermore I kept 2 other dictionaries to calculate percent uses across datasets.
first_layer_usage = defaultdict(int)
last_layer_usage = defaultdict(int)
# these two will store the values for all the datasets
all_first_layer_usages = dict()
all_last_layer_usages = dict()
def first_layer_update(module, input, output):
_, topk_index = t.topk(output, 2, dim=1)
# topk_list of of the shape [S_l, 2] where S_l is the length of the sequence
topk_list = topk_index.tolist()
# iterate over all the tokens in the sequence
for topk in topk_list:
expert_1, expert_2 = tuple(topk)
first_layer_usage[expert_1] += 1
first_layer_usage[expert_2] += 1
def last_layer_update(module, input, output):
_, topk_index = t.topk(output, 2, dim=1)
# topk_list of of the shape [S_l, 2] where S_l is the length of the sequence
topk_list = topk_index.tolist()
# iterate over all the tokens in the sequence
for topk in topk_list:
expert_1, expert_2 = tuple(topk)
last_layer_usage[expert_1] += 1
last_layer_usage[expert_2] += 1
And then got a bunch of datasets
imdb_dataset = load_dataset("stanfordnlp/imdb", split="test")
qa_dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
code_dataset = load_dataset("bigcode/bigcodebench", split="v0.1.0_hf")
And just ran them. The y-axis is the percentage of the dataset. The x-axis is the expert number. This is the graph for the last layer of experts.
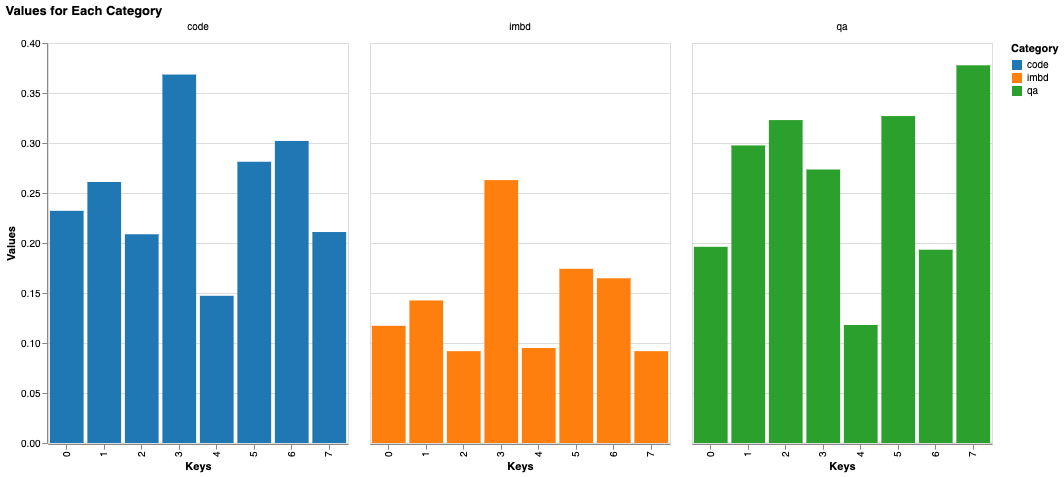
Once again I was quite disappointed here. Nothing to show really. Nothing to lead me on to something else. Code and IMDB Reviews oddly fire in similar fashions though. However when I tried to do this for more coding datasets, the trend did not hold up. Unfortunate.
What have I learned
- There is value in replicating for the sake of it
As the subtitle of this post indicates, sometimes it is worthwhile to just replicate experiments. There is so much more you learn from rewriting the code that the paper references. Not merely in terms of the experiment itself but also of the libraries that you use and the overall goal (i.e why it was worthwhile pursuing in the first place). I am quite sure I will adopt a strategy where every month I try and replicate the findings of some research paper I liked.
- Keeping track of whitepaper is extremely valuable
Keeping track of all the whitepaper that you read and find interesting is top of the my agenda for my little corner of the web. I intend to store and build a digital garden in public a la Maggie Appleton. In this digital garden, I will absolutely be keeping track of all the whitepaper that I read on the Internet and especially ones that I find salient or I'm gonna replicate.
- Reproducibilty should not be an after thought
With respect to both programming and research, if you're working on something and mid-way through Person X says they cannot build / reproduce or get mildly similar results to you - that's a hard stop. Complexity demon hath entired thy codebase. Big bad happened. I've learnt that in such cases, you must divert all attention to making sure it is reproducible for Person X and at least 1 other instance. DO NOT KEEP CHUGGING ALONG. Instead of pushing along with delivering features / fixes, focus on replication just like you would regular feature development.
I've learned this the hard way. If Person X cannot replicate now, you from the future most likely won't be able to either. Your experiments are moot then.
All right folks. Elvis has left the building.